Home
News
Publications
People
NeXuS
Blog
Contact
3
Steering Vectors are an Adversarial Attack Surface
Activation steering has become a popular way to control Large Language Model (LLM) behavior without fine-tuning. Since the technique is …
Abzal Aidakhmetov
,
Donato Crisostomi
,
Tommaso Mencattini
,
Adrian R. Minut
,
Iacopo Masi
,
Emanuele Rodolà
Cite
arXiv
Communicating Sound Through Natural Language
Natural language is widely used to describe, prompt, and control audio systems, but rarely serves as the representation carrying audio …
Emanuele Rossi
,
Emanuele Rodolà
Cite
arXiv
Demo
Multi-objective Evolutionary Merging Enables Efficient Reasoning Models
Reasoning models have demonstrated remarkable capabilities in solving complex problems by leveraging long chains of thought. However, …
Mario Iacobelli
,
Adrian R. Minut
,
Tommaso Mencattini
,
Donato Crisostomi
,
Andrea Santilli
,
Iacopo Masi
,
Emanuele Rodolà
Cite
arXiv
Zero-Shot Quantization via Weight-Space Arithmetic
We show that robustness to post-training quantization (PTQ) is a transferable direction in weight space. We call this direction the …
Daniele Solombrino
,
Antonio Andrea Gargiulo
,
Alessandro Zirilli
,
Luca Zhou
,
Adrian R. Minut
,
Emanuele Rodolà
Cite
arXiv
GitHub
Domain Elastic Transform: Bayesian Function Registration for High-Dimensional Scientific Data
Nonrigid registration is conventionally divided into point set registration, which aligns sparse geometries, and image registration, …
Osamu Hirose
,
Emanuele Rodolà
Cite
arXiv
GitHub
Activation Patching for Interpretable Steering in Music Generation
Understanding how large audio models represent music, and using that understanding to steer generation, is both challenging and …
Simone Facchiano
,
Giorgio Strano
,
Donato Crisostomi
,
Irene Tallini
,
Tommaso Mencattini
,
Fabio Galasso
,
Emanuele Rodolà
Cite
arXiv
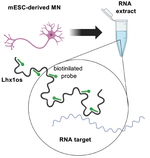
Decoding RNA-RNA Interactions: The Role of Low-Complexity Repeats and a Deep Learning Framework for Sequence-Based Prediction
RNA-RNA interactions (RRIs) are fundamental to gene regulation and RNA processing, yet their molecular determinants remain unclear. In …
Adriano Setti
,
Giorgio Bini
,
Valentino Maiorca
,
Flaminia Pellegrini
,
Gabriele Proietti
,
Dimitrios Miltiadis-Vrachnos
,
Alexandros Armaos
,
Julie Martone
,
Michele Monti
,
Giancarlo Ruocco
,
Emanuele Rodolà
,
Irene Bozzoni
,
Alessio Colantoni
,
Gian Gaetano Tartaglia
Cite
bioRxiv
GitHub
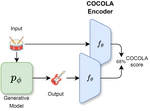
COCOLA: Coherence-Oriented Contrastive Learning of Musical Audio Representations
We present COCOLA (Coherence-Oriented Contrastive Learning for Audio), a contrastive learning method for musical audio representations …
Ruben Ciranni
,
Giorgio Mariani
,
Michele Mancusi
,
Emilian Postolache
,
Giorgio Fabbro
,
Emanuele Rodolà
,
Luca Cosmo
Cite
arXiv
GitHub
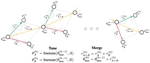
ATM: Improving Model Merging by Alternating Tuning and Merging
Model merging has recently emerged as a cost-efficient paradigm for multi-task learning. Among current approaches, task arithmetic …
Luca Zhou
,
Daniele Solombrino
,
Donato Crisostomi
,
Maria Sofia Bucarelli
,
Fabrizio Silvestri
,
Emanuele Rodolà
Cite
arXiv
GitHub
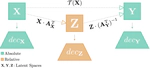
Latent Space Translation via Inverse Relative Projection
The emergence of similar representations between independently trained neural models has sparked significant interest in the …
Valentino Maiorca
,
Luca Moschella
,
Marco Fumero
,
Francesco Locatello
,
Emanuele Rodolà
Cite
arXiv
»
Cite
×