Multi-Source Diffusion Models for Simultaneous Music Generation and Separation
Abstract
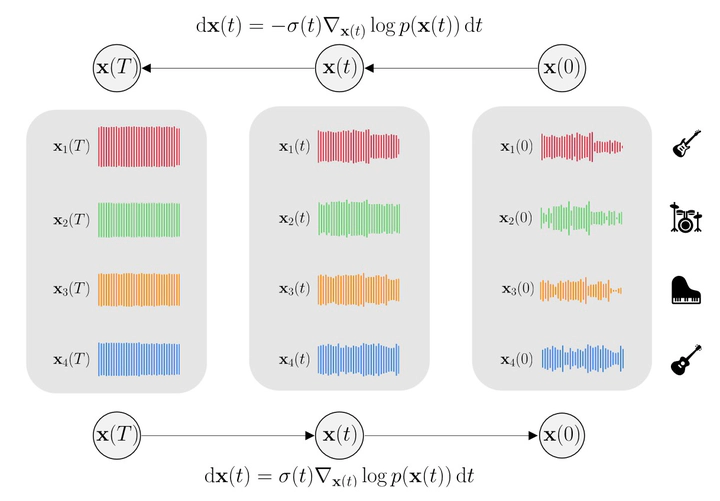
In this work, we define a diffusion-based generative model capable of both music synthesis and source separation by learning the score of the joint probability density of sources sharing a context. Alongside the classic total inference tasks (i.e., generating a mixture, separating the sources), we also introduce and experiment on the partial generation task of source imputation, where we generate a subset of the sources given the others (e.g., play a piano track that goes well with the drums). Additionally, we introduce a novel inference method for the separation task based on Dirac likelihood functions. We train our model on Slakh2100, a standard dataset for musical source separation, provide qualitative results in the generation settings, and showcase competitive quantitative results in the source separation setting. Our method is the first example of a single model that can handle both generation and separation tasks, thus representing a step toward general audio models.
Irene Tallini
PostDoctoral Researcher, Area Science Park, Trieste
I’m a Computer Science PhD with Math Bachelor and passion. Right now I’m working on AI for music and vector quantile regression. I like to sing, also.
Emilian Postolache
Lead Machine Learning Researcher, IRIS Audio
Lead Machine Learning Researcher @ Iris Audio
Michele Mancusi
PostDoctoral Researcher
PhD Student @SapienzaRoma CS | Intern @Musixmatch | Intern @Microsoft | Research Scientist @Sony | Senior Research Scientist @Moises