Abstract
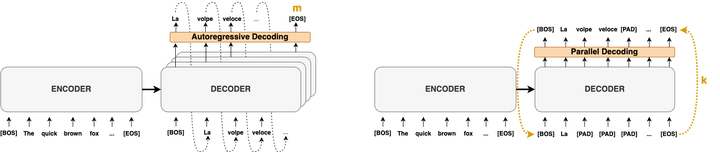
Autoregressive decoding limits the efficiency of transformers for Machine Translation (MT). The community proposed specific network architectures and learning-based methods to solve this issue, which are expensive and require changes to the MT model, trading inference speed at the cost of the translation quality. In this paper, we propose to address the problem from the point of view of decoding algorithms, as a less explored but rather compelling direction. We propose to reframe the standard greedy autoregressive decoding of MT with a parallel formulation leveraging Jacobi and Gauss-Seidel fixed-point iteration methods for fast inference. This formulation allows to speed up existing models without training or modifications while retaining translation quality. We present three parallel decoding algorithms and test them on different languages and models showing how the parallelization introduces a speedup up to 38% w.r.t. the standard autoregressive decoding and nearly 2x when scaling the method on parallel resources. Finally, we introduce a decoding dependency graph visualizer (DDGviz) that let us see how the model has learned the conditional dependence between tokens and inspect the decoding procedure.
Andrea Santilli
Senior Research Engineer, NVIDIA
PhD Student passionate about natural language processing, representation learning and machine intelligence.
Emilian Postolache
Lead Machine Learning Researcher, IRIS Audio
Lead Machine Learning Researcher @ Iris Audio
Michele Mancusi
PostDoctoral Researcher
PhD Student @SapienzaRoma CS | Intern @Musixmatch | Intern @Microsoft | Research Scientist @Sony | Senior Research Scientist @Moises