Abstract
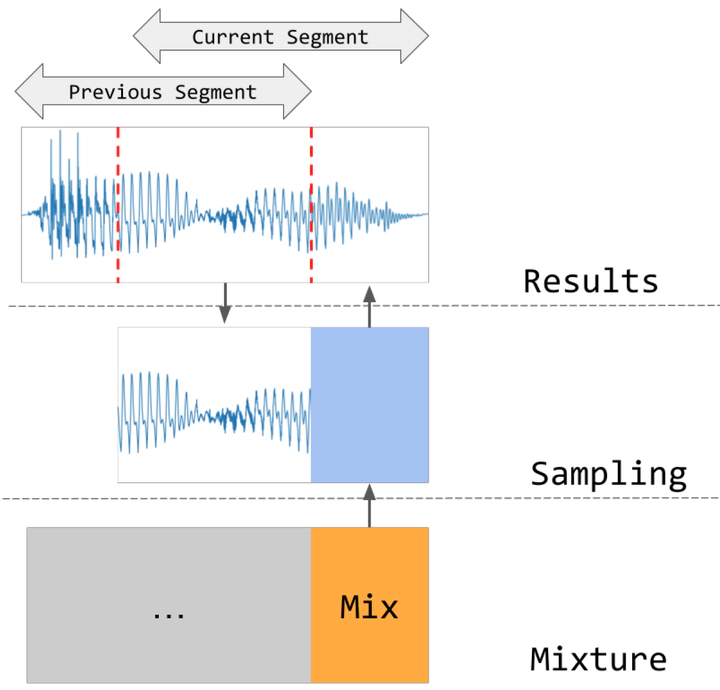
In recent studies, diffusion models have shown promise as priors for solving audio inverse problems, including source separation. These models allow us to sample from the posterior distribution of a target signal given an observed signal by manipulating the diffusion process. However, when separating audio sources of the same type, such as duet singing voices, the prior learned by the diffusion process may not be sufficient to maintain the consistency of the source identity in the separated audio. For example, the singer may change from one to another from time to time. Tackling this problem will be useful for separating sources in a choir, or a mixture of multiple instruments with similar timbre, without acquiring large amounts of paired data. In this paper, we examine this problem in the context of duet singing voices separation, and propose a method to enforce the coherency of singer identity by splitting the mixture into overlapping segments and performing posterior sampling in an auto-regressive manner, conditioning on the previous segment. We evaluate the proposed method on the MedleyVox dataset with different overlap ratios, and show that the proposed method outperforms naive posterior sampling baseline. Our source code and the pre-trained model are publicly available.
Emilian Postolache
Lead Machine Learning Researcher, IRIS Audio
Lead Machine Learning Researcher @ Iris Audio