Abstract
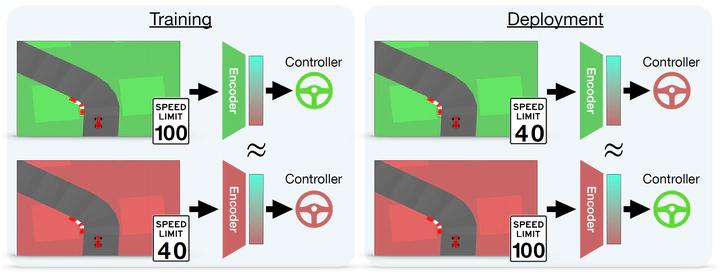
Visual Reinforcement Learning is a popular and powerful framework that takes full advantage of the Deep Learning breakthrough. However, it is also known that variations in the input (e.g., different colors of the panorama due to the season of the year) or the task (e.g., changing the speed limit for a car to respect) could require complete retraining of the agents. In this work, we leverage recent developments in unifying latent representations to demonstrate that it is possible to combine the components of an agent, rather than retrain it from scratch. We build upon the recent relative representations framework and adapt it for Visual RL. This allows us to create completely new agents capable of handling environment-task combinations never seen during training. Our work paves the road toward a more accessible and flexible use of reinforcement learning.
Antonio Pio Ricciardi
PostDoctoral Researcher
Luca Moschella
Research Scientist, Apple
PhD Student @SapienzaRoma CS | Intern @NVIDIA Toronto Lab | @NNAISENSE