Abstract
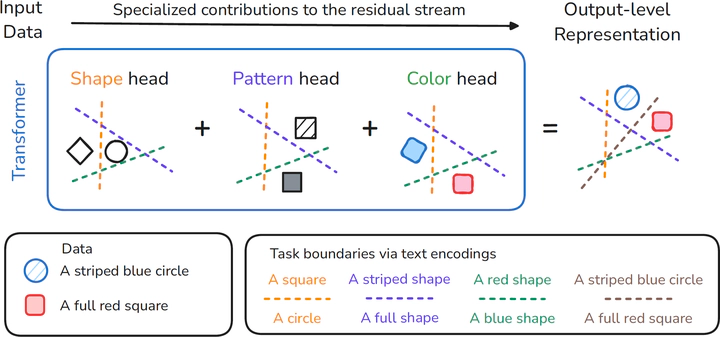
When examined through the lens of their residual streams, a puzzling property emerges in transformer networks: residual contributions (e.g., attention heads) sometimes specialize in specific tasks or input attributes. In this paper, we analyze this phenomenon in vision transformers, focusing on the spectral geometry of residuals, and explore its implications for modality alignment in vision-language models. First, we link it to the intrinsically low-dimensional structure of visual head representations, zooming into their principal components and showing that they encode specialized roles across a wide variety of input data distributions. Then, we analyze the effect of head specialization in multimodal models, focusing on how improved alignment between text and specialized heads impacts zero-shot classification performance. This specialization-performance link consistently holds across diverse pre-training data, network sizes, and objectives, demonstrating a powerful new mechanism for boosting zero-shot classification through targeted alignment. Ultimately, we translate these insights into actionable terms by introducing ResiDual, a technique for spectral alignment of the residual stream. Much like panning for gold, it lets the noise from irrelevant unit principal components (i.e., attributes) wash away to amplify task-relevant ones. Remarkably, this dual perspective on modality alignment yields fine-tuning level performances on different data distributions while modeling an extremely interpretable and parameter-efficient transformation, as we extensively show on more than 50 (pre-trained network, dataset) pairs.