Abstract
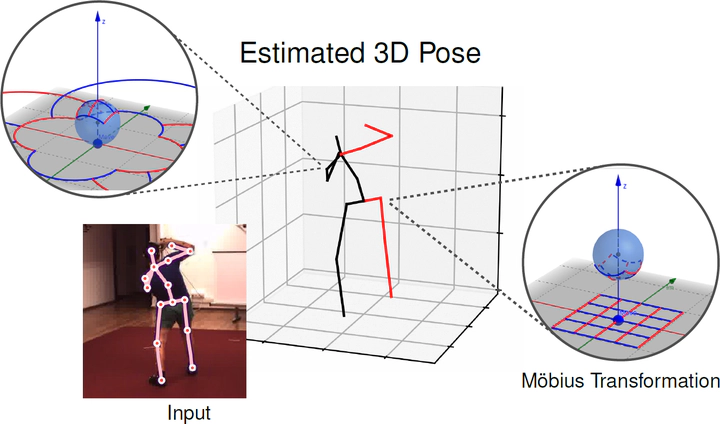
3D human pose estimation is fundamental to understanding human behavior. Recently, promising results have been achieved by graph convolutional networks (GCNs), which achieve state-of-the-art performance and provide rather light-weight architectures. However, a major limitation of GCNs is their inability to encode all the transformations between joints explicitly. To address this issue, we propose a novel spectral GCN using the Möbius transformation (Möbius-GCN). In particular, this allows us to directly and explicitly encode the transformation between joints, resulting in a significantly more compact representation. Compared to even the lightest architectures so far, our novel approach requires 90–98% fewer parameters, i.e. our lightest MöbiusGCN uses only 0.042M trainable parameters. Besides the drastic parameter reduction, explicitly encoding the transformation of joints also enables us to achieve state-of-the-art results. We evaluate our approach on the two challenging pose estimation benchmarks, Human3.6M and MPI-INF-3DHP, demonstrating both state-of-the-art results and the generalization capabilities of MöbiusGCN.