Abstract
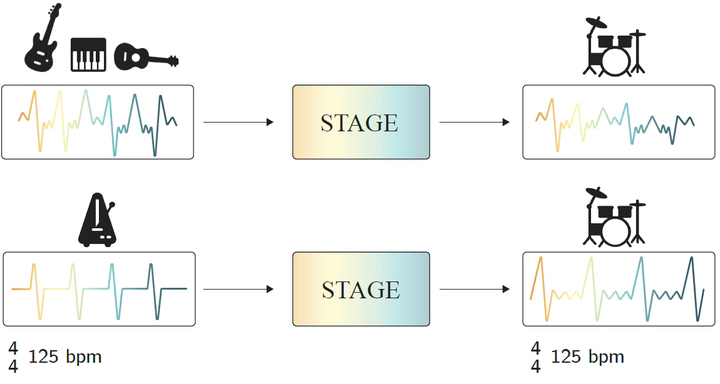
Recent advances in generative models have made it possible to create high-quality, coherent music, with some systems delivering production-level output. Yet, most existing models focus solely on generating music from scratch, limiting their usefulness for musicians who want to integrate such models into a human, iterative composition workflow. In this paper we introduce STAGE, our STemmed Accompaniment GEneration model, fine-tuned from the state-of-the-art MusicGen to generate single-stem instrumental accompaniments conditioned on a given mixture. Inspired by instruction-tuning methods for language models, we extend the transformer’s embedding matrix with a context token, enabling the model to attend to a musical context through prefix-based conditioning. Compared to the baselines, STAGE yields accompaniments that exhibit stronger coherence with the input mixture, higher audio quality, and closer alignment with textual prompts. Moreover, by conditioning on a metronome-like track, our framework naturally supports tempo-constrained generation, achieving state-of-the-art alignment with the target rhythmic structure–all without requiring any additional tempo-specific module. As a result, STAGE offers a practical, versatile tool for interactive music creation that can be readily adopted by musicians in real-world workflows.
Giorgio Strano
PhD Student
Donato Crisostomi
PhD Student
PhD student @ Sapienza, University of Rome | former Applied Science intern @ Amazon Search, Luxembourg | former Research Science intern @ Amazon Alexa, Turin
Michele Mancusi
PostDoctoral Researcher
PhD Student @SapienzaRoma CS | Intern @Musixmatch | Intern @Microsoft | Research Scientist @Sony | Senior Research Scientist @Moises