Abstract
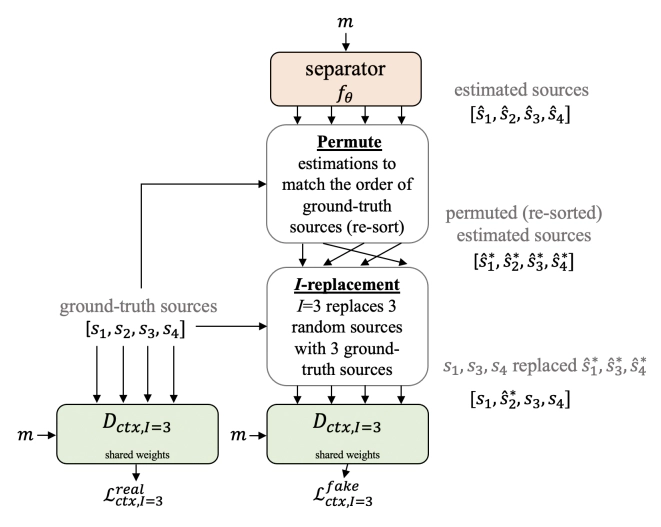
Universal sound separation consists of separating mixes with arbitrary sounds of different types, and permutation invariant training (PIT) is used to train source agnostic models that do so. In this work, we complement PIT with adversarial losses but find it challenging with the standard formulation used in speech source separation. We overcome this challenge with a novel I-replacement context-based adversarial loss, and by training with multiple discriminators. Our experiments show that by simply improving the loss (keeping the same model and dataset) we obtain a non-negligible improvement of 1.4 dB SI-SNRi in the reverberant FUSS dataset. We also find adversarial PIT to be effective at reducing spectral holes, ubiquitous in mask-based separation models, which highlights the potential relevance of adversarial losses for source separation.
Emilian Postolache
Lead Machine Learning Researcher, IRIS Audio
Lead Machine Learning Researcher @ Iris Audio