Abstract
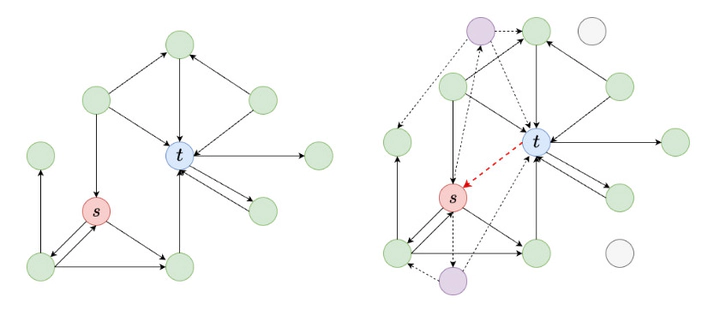
In this study, we introduce SAVAGE, a novel framework for sparse vicious adversarial link prediction attacks in graph neural networks (GNNs). While GNNs have been successful in link prediction tasks, they are susceptible to adversarial attacks where malicious nodes attempt to manipulate recommendations for a target victim. SAVAGE optimizes the attacker’s goal to maximize attack effectiveness while minimizing the required malicious resources. Unlike existing methods with static resource-based upper bounds, SAVAGE employs a sparsity-enforcing mechanism to reduce the number of malicious nodes needed for the attack. Extensive experiments on real-world and synthetic datasets demonstrate the optimal tradeoff achieved by SAVAGE between a high attack success rate and the number of malicious nodes utilized. Furthermore, we demonstrate that SAVAGE can successfully target non-GNN-based link prediction systems, even those unknown at the time of the attack. This showcases the transferability of SAVAGE-generated attacks to other black-box methods for link prediction, highlighting its applicability across different real-world scenarios.