Home
News
Publications
People
NeXuS
Blog
Contact
3
Demystifying Mergeability: Interpretable Properties to Predict Model Merging Success
Model merging combines knowledge from separately fine-tuned models, yet success factors remain poorly understood. While recent work …
Luca Zhou
,
Bo Zhao
,
Rose Yu
,
Emanuele Rodolà
Cite
arXiv
Multi-Way Representation Alignment
The Platonic Representation Hypothesis suggests that independently trained neural networks converge to increasingly similar latent …
Akshit Achara
,
Tatiana Gaintseva
,
Mateo Mahaut
,
Pritish Chakraborty
,
Viktor Stenby Johansson
,
Melih Barsbey
,
Emanuele Rodolà
,
Donato Crisostomi
Cite
arXiv
Activation Patching for Interpretable Steering in Music Generation
Understanding how large audio models represent music, and using that understanding to steer generation, is both challenging and …
Simone Facchiano
,
Giorgio Strano
,
Donato Crisostomi
,
Irene Tallini
,
Tommaso Mencattini
,
Fabio Galasso
,
Emanuele Rodolà
Cite
arXiv
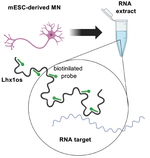
Decoding RNA-RNA Interactions: The Role of Low-Complexity Repeats and a Deep Learning Framework for Sequence-Based Prediction
RNA-RNA interactions (RRIs) are fundamental to gene regulation and RNA processing, yet their molecular determinants remain unclear. In …
Adriano Setti
,
Giorgio Bini
,
Valentino Maiorca
,
Flaminia Pellegrini
,
Gabriele Proietti
,
Dimitrios Miltiadis-Vrachnos
,
Alexandros Armaos
,
Julie Martone
,
Michele Monti
,
Giancarlo Ruocco
,
Emanuele Rodolà
,
Irene Bozzoni
,
Alessio Colantoni
,
Gian Gaetano Tartaglia
Cite
bioRxiv
GitHub
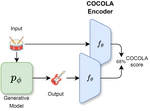
COCOLA: Coherence-Oriented Contrastive Learning of Musical Audio Representations
We present COCOLA (Coherence-Oriented Contrastive Learning for Audio), a contrastive learning method for musical audio representations …
Ruben Ciranni
,
Giorgio Mariani
,
Michele Mancusi
,
Emilian Postolache
,
Giorgio Fabbro
,
Emanuele Rodolà
,
Luca Cosmo
Cite
arXiv
GitHub
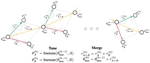
ATM: Improving Model Merging by Alternating Tuning and Merging
Model merging has recently emerged as a cost-efficient paradigm for multi-task learning. Among current approaches, task arithmetic …
Luca Zhou
,
Daniele Solombrino
,
Donato Crisostomi
,
Maria Sofia Bucarelli
,
Fabrizio Silvestri
,
Emanuele Rodolà
Cite
arXiv
GitHub
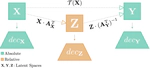
Latent Space Translation via Inverse Relative Projection
The emergence of similar representations between independently trained neural models has sparked significant interest in the …
Valentino Maiorca
,
Luca Moschella
,
Marco Fumero
,
Francesco Locatello
,
Emanuele Rodolà
Cite
arXiv
From Bricks to Bridges: Product of Invariances to Enhance Latent Space Communication
It has been observed that representations learned by distinct neural networks conceal structural similarities when the models are …
Irene Cannistraci
,
Luca Moschella
,
Marco Fumero
,
Valentino Maiorca
,
Emanuele Rodolà
Cite
PDF
URL
ICLR 2024 spotlight
GSEdit: Efficient Text-Guided Editing of 3D Objects via Gaussian Splatting
We present GSEdit, a pipeline for text-guided 3D object editing based on Gaussian Splatting models. Our method enables the editing of …
Francesco Palandra
,
Andrea Sanchietti
,
Daniele Baieri
,
Emanuele Rodolà
Cite
arXiv
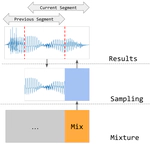
Zero-Shot Duet Singing Voices Separation with Diffusion Models
In recent studies, diffusion models have shown promise as priors for solving audio inverse problems, including source separation. These …
Chin-Yun Yu
,
Emilian Postolache
,
Emanuele Rodolà
,
Gyorgy Fazekas
Cite
PDF
arXiv
GitHub
»
Cite
×