Home
News
Publications
People
NeXuS
Blog
Contact
1
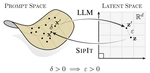
Navigating the Latent Space Dynamics of Neural Models
Neural networks transform high-dimensional data into compact, structured representations, often modeled as elements of a lower …
Marco Fumero
,
Luca Moschella
,
Emanuele Rodolà
,
Francesco Locatello
Cite
arXiv
ICLR 2026 Oral
Language Models are Injective and Hence Invertible
Transformer components such as non-linear activations and normalization are inherently non-injective, suggesting that different inputs …
Giorgos Nikolaou
,
Tommaso Mencattini
,
Donato Crisostomi
,
Andrea Santilli
,
Yannis Panagakis
,
Emanuele Rodolà
Cite
arXiv
Thread
GitHub
Implicit Inversion turns CLIP into a Decoder
CLIP is a discriminative model trained to align images and text in a shared embedding space. Due to its multimodal structure, it serves …
Antonio D'Orazio
,
Maria Rosaria Briglia
,
Donato Crisostomi
,
Dario Loi
,
Emanuele Rodolà
,
Iacopo Masi
Cite
arXiv
GitHub
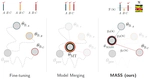
MASS: MoErging through Adaptive Subspace Selection
Model merging has recently emerged as a lightweight alternative to ensembling, combining multiple fine-tuned models into a single set …
Donato Crisostomi
,
Alessandro Zirilli
,
Antonio Andrea Gargiulo
,
Maria Sofia Bucarelli
,
Simone Scardapane
,
Fabrizio Silvestri
,
Iacopo Masi
,
Emanuele Rodolà
Cite
arXiv
Video Unlearning via Low-Rank Refusal Vector
Video generative models democratize the creation of visual content through intuitive instruction following, but they also inherit the …
Simone Facchiano
,
Stefano Saravalle
,
Matteo Migliarini
,
Edoardo De Matteis
,
Alessio Sampieri
,
Andrea Pilzer
,
Emanuele Rodolà
,
Indro Spinelli
,
Luca Franco
,
Fabio Galasso
Cite
arXiv
GitHub
EuleroDec: A Complex-Valued RVQ-VAE for Efficient and Robust Audio Coding
Audio codecs power discrete music generative modelling, music streaming and immersive media by shrinking PCM audio to …
Luca Cerovaz
,
Michele Mancusi
,
Emanuele Rodolà
Cite
arXiv
Model Merging Improves Zero-Shot Generalization in Bioacoustic Foundation Models
Foundation models capable of generalizing across species and tasks represent a promising new frontier in bioacoustics, with NatureLM …
Davide Marincione
,
Donato Crisostomi
,
Roberto Dessi
,
Emanuele Rodolà
,
Emanuele Rossi
Cite
arXiv
URL
GitHub
Spotlight (top 15%)
Two-Scale Latent Dynamics for Recurrent-Depth Transformers
Recurrent-depth transformers scale test-time compute by iterating latent computations before emitting tokens. We study the geometry of …
Francesco Pappone
,
Donato Crisostomi
,
Emanuele Rodolà
Cite
arXiv
Membership and Dataset Inference Attacks on Large Audio Generative Models
Generative audio models, based on diffusion and autoregressive architectures, have advanced rapidly in both quality and expressiveness. …
Jakub Proboszcz
,
Paweł Kochański
,
Karol Korszun
,
Katarzyna Stankiewicz
,
Donato Crisostomi
,
Giorgio Strano
,
Emanuele Rodolà
,
Kamil Deja
,
Jan Dubiński
Cite
Implicit-ARAP: Efficient Handle-Guided Neural Field Deformation via Local Patch Meshing
Neural fields have emerged as a powerful representation for 3D geometry, enabling compact and continuous modeling of complex shapes. …
Daniele Baieri
,
Filippo Maggioli
,
Emanuele Rodolà
,
Simone Melzi
,
Zorah Laehner
Cite
arXiv
GitHub
»
Cite
×